Census Prognose baseres på geografiske distrikter. Fremskrivningerne baseres på populationen på den valgte startdato og de enkelte borgeres adressetilhør i forhold til distrikterne.
LIFA anbefaler at der anvendes distrikter med en populationsstørrelse på minimum 1000, men mindre områder kan også anvendes.
OBS: Hvis den anvendte prognosedistriktsinddeling består af mere end 50 polygoner skal LIFA kontaktes.
Det er i den forbindelse nødvendigt at justere på forskellige standardværdier i prognosesystemet for at tillade et stort antal polygoner. Denne opgave kan kun udføres af LIFA.
Mange vælger at udføre prognoseberegningerne på skoledistrikter, da populationsudviklingen i denne inddeling er central i den kommunale budgetlægning.
Ønsker man at udføre prognoseberegningen på mindre områder end skoledistrikter, anbefales det at disse underområder geografisk kan aggregeres op til "fulde" skoledistrikter.
På denne måde kan man skalere sine prognoseresultater sømløst efter behov.
Særligt vedr. distrikter til skoleprognose
Alle de distriktsinddelinger der skal danne grundlag for skoleprognoser, skal respektere grænserne for de administrative indskolingsdistrikter (FKG-skoledistrikter med starttrin_kode = 11 - OBS: indskolingsdistrikter må ikke overlappe!).
Dvs. at et prognosedistrikt IKKE må krydse en indskolingsdistriktsgrænse hvis det skal anvendes til en skoleprognose.
Dertil skal geodata-filen der indlæses til skoleprognosebrug indeholde en kolonne der viser hvilket Skoledistrikt (udd_distrikt_nr) prognosedistriktet ligger i/referer til.
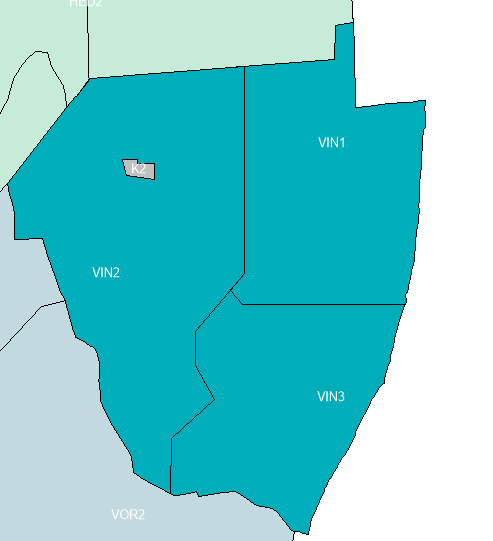
Illustrationen nedenfor viser tre prognosedistrikter der tilsammen udgør ét skoledistrikt.
Attributdata i geodatafilen indeholder en kolonne der viser hvilket skoledistrikt prognosedistriktet vedrører.
Den fjerde række er et konstantområde (K2) som ligeledes er "indlejret" i pågældende skoledistrikt.
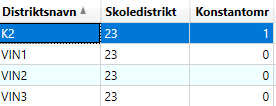
Informationen om den kolonne der fortæller hvilke skoleprognosedistrikter der refererer til hvilke skoledistrikter skal angives i Census Manager under Prognose-fanen.
Laver man skoleprognosen direkte på skoledistrikter, udpeges blot den eksisterende kolonne med skoledistriktsnavnet i Census Manager.
Se eksempel på opbygning af et prognosedistrikt med referencer til indskolingsdistrikter her:
Konstantområder
I Census Prognose er det muligt at operere med såkaldte konstantområder.
Et konstantområde skal forstås som et geografisk område hvor der ikke forventes en normal befolkningsudvikling - eks. plejecentre, døgninstitutioner eller store kollegier.
I sådanne områder vil befolkningen ikke over tid blive større eller mindre, få en ny alderssammensætning, føde børn mv på samme vis som i andre områder.
Derfor er det vigtigt at få lokaliseret sådanne områder og indeholde dem i det prognosedistriktssæt der anvendes til prognoseberegningen.
Før indlæsning af prognose- eller skoledistrikter til løsningen er det derfor nødvendigt at lave lidt tilpasninger af de geografiske data i GIS.
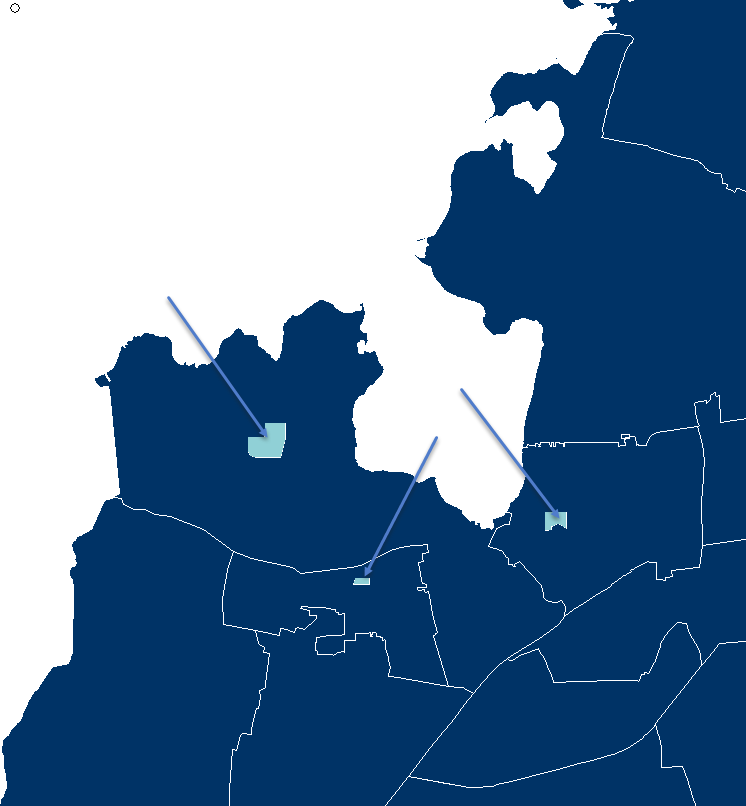
Nedenfor ses et eksempelt på en skoledistriktsinddeling (mørkeblå områder).
Dertil er der oprettet tre konstantområder (lysblå områder) og der er klippet hul i skoledistrikterne så disse ikke overlapper med kontantområderne.
Generelt må ingen polygoner overlappe hinanden i et prognosedistriktssæt.
For at systemet kan behandle distrikterne korrekt er det nødtvendigt at tilpasse attributdata i GIS, således at der forekommer en kolonne med datatype: INT/heltal.
I denne "Konstantomr-kolonne" inddateres værdien: 1 på rækker vedr. konstantområder og værdien: 0 på øvrige rækker.
Det er vigtigt at overholde disse krav for at systemet fungerer korrekt - værdierne må således ikke være eks. Ja/Nej - TRUE/FALSE el. lign.
OBS: Det er kritisk at konstantområder ikke har det samme navn som et ordinært prognosedistrikt i den kolonne der angives som niveaunavn i Census Manager.
Hvis dette ikke overholdes, bliver konstantområdet slået sammen med det prognosedistrikt det deler navn med og derfor ikke behandlet som et konstantområde.
Hvis man anvender flere forskellige distriktsinddelinger til prognoseudarbejdelse, er det nødvendigt at konstantområderne er ens for alle inddelinger.
Det er ligeledes kritisk at grænserne for et konstantområde IKKE danner grænse til et prognosedistrikt, men altid er omsluttet entydigt af en prognosedistrikt.
Se eksempel på opbygning af et prognosedistrikt med konstantområder her:
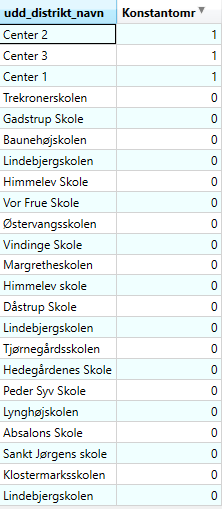
I Census Manager kan man efterfølgende udpege den relevante kolonne som viser hvilke områder der er konstantområder. Se here her